This is a technique pulled from KnowledgeBase, a digital accessibility repository available through TPGi’s ARC Platform. KnowledgeBase is maintained and consistently updated by our experts, and can be accessed by anyone with an ARC Platform subscription. Contact us to learn more about KnowledgeBase or the ARC Platform.
Speech recognition software allows people to navigate and interact with web content using spoken commands. This kind of assistive technology is primarily used by people who have motor disabilities, such as quadriplegia (paralysis of the limbs), missing hands or limbs, or limited dexterity due to a condition such as arthritis. In some cases it may be used in combination with other assistive technology, such as a switch device, and it is also used by some people with cognitive disabilities.
Most desktop and mobile operating systems have some kind of speech recognition software built in, but for the purposes of this article, we’ll focus on using Dragon. Dragon supports a sophisticated range of text input and editing commands, however the bulk of the article will look at commands used for navigating content and activating controls.
In order to test that web content is accessible to speech recognition software, we must first understand how the software is used. Dragon supports three different methods for interacting with web content:
- Activating controls by speaking their text.
- Using spoken commands for keyboard navigation such as Tab and Enter.
- Using spoken commands that control the mouse pointer.
Activating controls by speaking their text is the quickest and easiest for users, such as clicking a “Products” link by saying Click products
. If there are multiple links with the same text (or if a generic command such as Click link
is used), then Dragon will highlight all the matching links with a number. The user can then activate the one they want by saying that number.

Identifying controls by their text
It’s important to note here that modern speech recognition software uses a control’s accessible text to identify it. The accessible text of a control is usually its visible text, however if the control has non-visible accessible text, then this may be used for its speakable command instead (or as well).
It’s a common practice to disambiguate multiple links with the same visible text, by adding non-visible text that provides more context. This benefits screen reader users by ensuring that each link is unique and makes sense when read out of context:
<a href="/products" aria-label="Read more about our products">Read more</a>
...
<a href="/services" aria-label="Read more about our services">Read more</a>This non-visible text is also available to speech recognition software. If a Dragon user were to say Click read more
, then the software would highlight both of those links with numbers, as we saw earlier. They could also say Click read more about our products
to activate that link uniquely, but how would they know to say that, when that text is not visible?
That example is not inaccessible, because it only takes two commands to find the right link. Still, it’s better usability for speech recognition users if the visible text of each control is unique. Similarly, in the case of form controls such as text inputs, a speech recognition user can navigate to inputs that don’t have a visible or associated label, but this is not as quick and easy as it is for an input with a programmatically associated text label:
<label for="fullname">Full name</label>
<input type="text" id="fullname" name="fullname">If a control has both visible text and non-visible accessible text, as in the link examples earlier, it is vital that the accessible text begins with the visible text. In the following example, the spoken command Click read more
might not be able to find the link, because the text “read more” is not contained within the link’s accessible text:
<a href="/products" aria-label="Learn about our products">Read more</a>However it will be able to find the link if the accessible text begins with the visible text:
<a href="/products" aria-label="Read more about our products">Read more</a>2.5.3 Label in Name only requires that the accessible text contains the visible text, however some speech recognition software (such as iOS Voice Control) can only recognize the element if the accessible text begins with the visible text, therefore this pattern is the recommended best practice.
Navigating with spoken keyboard commands
Secondary to direct activation commands, speech recognition users can speak keyboard navigation commands, such as Tab
and Press enter
, to interact in the same way as a physical keyboard or switch user.
So in order for web content to be easily accessible to speech recognition users, it must be accessible to keyboard users.
Navigating with spoken mouse commands
Dragon also has features that allow the user to control a mouse pointer or pseudo-pointer. One example of this is the Mouse Grid feature. Saying mouse grid
overlays the page with a grid of 9 numbered squares; the user can then speak one of those numbers to create a deeper grid of 9 squares in that space. This process continues until the mouse grid is in a precise enough location to click
a specific element.
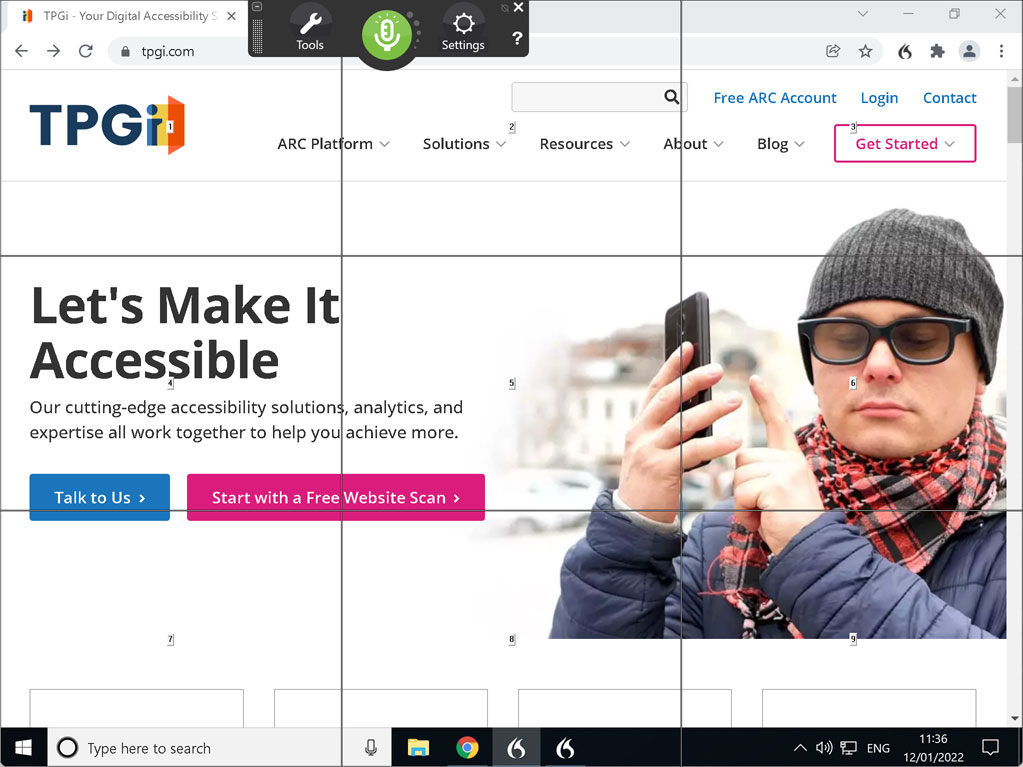
This form of interaction can be used for controls that do not have visible text, such as graphical buttons, as well as for controls that are not focusable at all. But as you can imagine, it’s quite tedious and time-consuming to isolate controls in this way. It’s much easier for users if controls are focusable, and either have visible text labels, or have obvious and intuitive accessible text that a user could guess. For example, if a Facebook share button includes the word “Facebook” in its accessible text, then a user could reasonably guess that they can say Facebook
to activate that control.
Dragon even has direct mouse control commands, such as Move mouse down
(which slowly animates the pointer until the user says Stop
; the speed can also be changed with commands such as Faster
and Slower
). These commands can be used to interact with content that is not keyboard accessible, however using this feature is even more tedious and time-consuming than Mouse Grid, and additionally requires careful timing on the user’s part. This does not easily lend itself to mouse interactions that require precision control (such as drag and drop), so any such content should also have obvious and intuitive keyboard equivalents (which they should have anyway).
Inappropriately hidden content
It’s clearly implied that interacting with speech commands requires vision. Voice recognition users are necessarily sighted, so that they can see things like text labels and focus position. If those things are obscured, it will be very difficult for speech recognition users to interact with the content, just as it would be for sighted keyboard users.
One common problem here is the use of sticky headers, which can overlap and obscure focusable content as the page scrolls down. Sticky headers should be avoided. Another common issue is where modal dialogs do not trap focus within the dialog, making it possible to navigate to content that’s hidden behind the dialog. Just as for sighted keyboard users, they will then be in a situation where the focus could move to or activate an element they cannot see. Modal dialogs should always trap focus within the dialog while they’re open.
Element semantics
This presumption of sight might lead us to think that the underlying semantics of web content, which are so crucial to non-sighted screen reader users, are not relevant to sighted speech recognition users. However that is not the case. We’ve already seen examples of this in the difference between a control’s accessible text and its visible text, and there are also cases where semantics such as role and state are equally important to speech recognition.
Commands for activating specific types of control, such as radio buttons and checkboxes, rely on the underlying semantics of those controls. A native checkbox implemented with <input type="checkbox"> would respond to the Click checkbox
command, and since Dragon also supports ARIA (as of Version 1.3 or later), a custom checkbox implemented with role="checkbox" would also work as expected. However a custom checkbox which does not have the correct semantics, but simply looks like a checkbox, would not respond to this command. So it’s just as important for speech recognition users, as it is for screen readers users, that custom controls have the correct semantics.
It’s also worth considering the benefits of consistent visual affordance, i.e. that an element looks like what it is. If an element looks like a button, but is actually a styled link, then a speech recognition user would not be able to use the Click button
command to activate that control, when it looks like that should work. This is not a WCAG failure, however other things being equal, it’s better to use styles that are visually consistent with an element’s function.
WCAG requirements
Taking all these different scenarios into consideration, there are quite a few WCAG Success Criteria that are relevant to speech recognition users, including all SCs which relate to keyboard accessibility, as well as a number of SCs relating to element semantics and interaction limitations:
Level A
- 1.3.1 Info and Relationships
- 2.1.1 Keyboard
- 2.1.2 No Keyboard Trap
- 2.2.1 Timing Adjustable
- 2.4.1 Bypass Blocks
- 2.4.2 Page Titled
- 2.4.3 Focus Order
- 2.4.4 Link Purpose (In Context)
- 2.5.1 Pointer Gestures
- 2.5.2 Pointer Cancellation
- 2.5.3 Label in Name
- 2.5.4 Motion Actuation
- 3.2.1 On Focus
- 3.2.2 On Input
- 4.1.2 Name, Role, Value
Level AA
- 1.3.5 Identify Input Purpose
- 1.4.13 Content on Hover or Focus
- 2.4.7 Focus Visible
- 3.2.4 Consistent Identification
- 3.3.3 Error Suggestion
- 3.3.4 Error Prevention (Legal, Financial, Data)
- 4.1.3 Status Messages
Level AAA
Resources
- Read this article in ARC (must be an ARC Essentials or Enterprise subscriber)
- Dragon Speech Recognition Software
- Web browser basics (Dragon Help)
- Browsing with speech recognition
Comments
Thank you for this detailed guide on testing with speech recognition.